
Intro
This is one of my favorite topics as of late – Clean Architecture, the Do’s and Don’ts of how to write awesome software. At some point in your software development career, you’ll want to start taking things to the next level. That one liner might not be as magical anymore; or maybe you’re hazed from maintaining a production application, where its source is all in one file.
Either way, you’ve seen 1000’s of tutorials on how to write MVC applications, Web API’s and more; but most of them focus on teaching the framework/tooling and not the big picture. You’re left wondering how it all pieces together cleanly, in a way that you would actually want to bring it back to the workplace and share with your colleagues. If this sounds like you, then you’ve come to the right place.
Bob Ross
Who could be better to showcase clean architecture, other than Bob Ross? It’s all about drawing lines and trying not to make mistakes… but if you do, make the best of them!
We don’t make mistakes, just happy little accidents – Bob Ross
The Project
Introducing my latest open-source example project, Clean Architecture! It can be found on GitHub and it’s also hosted for you to test out live right here.
Clean Architecture is an example project to showcase how you would piece together different layers in a small, medium and even large sized application. It makes an attempt to adhere to recommended software architecture principles, such as SOLID and DDD. You’ll notice the application is split into a classic 3 Tier, Multi-Layer application which draws the lines between each major component of the application.
Rather than a task list, or to-do application, I went with a simple blog example. In the app, you can view a list of article excerpts, read the full article, and even create new articles… with images and categories.
The Architecture
The application features 3 layers – ClientWeb, a Razor Pages web application, Core contains the business logic, all the models and interfaces. Lastly, Infrastructure is our ORM and Logging implementations.
Below is the overall structure of the application: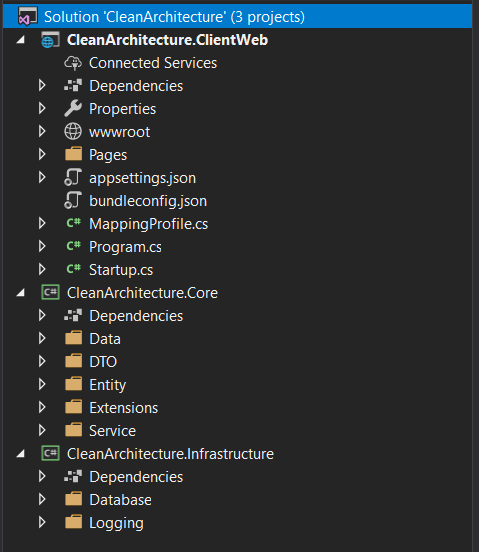
Data Flow
Like most examples you see online, the database implementation and classes are mixed together with the rest of the business logic. This violates the Single Responsibility Principle and should be moved into its own project.
Another issue with the example style approach, is that the database models are used in the UI and services – this can cause issues when you want to change the database schema, or even the UI. Instead, utilize View Models, DTO, and Entity objects. This way both the UI and the data layer can be changed independently from each other; they are no longer tightly coupled.
I find this part initially leaves people feeling like it’s a lot of extra work, and they don’t want to have multiple classes for a single object, etc. I get it; however, it comes with great benefits that should be considered. Having the models compartmentalized into their respective use cases will simplify the code and allow for greater flexibility in the long run.
Mapping
To make mapping between our various models a breeze, AutoMapper was added to the application. AutoMapper uses reflection to map values from one object to another, without having to know each property beforehand. This saves me from otherwise writing a ton of boilerplate code, mapping our entities to our DTO’s.
Dependency Injection and IoC
Every single dependency is injected via constructor injection. This means, every single dependency has its life cycle managed by the framework and can be swapped out with test/mock versions. The application is now decoupled and inherently more flexible.
Combining this with the use of interfaces, I can define the inputs and outputs of the application. With this amount of control, I am able to swap out entire implementations without affecting the rest of the code base. The application’s maintainability has now increased two-fold.
I’m making use of the built-in dependency injection container, provided by Microsoft.Extensions.DependencyInjection. Dependencies and their life cycle are managed by the framework and defined in the Startup.cs class:
public void ConfigureServices(IServiceCollection services)
{
// Repositories
services.AddScoped<IGenericRepository<ArticleEntity>, GenericRepository<ArticleEntity>>();
services.AddScoped<IGenericRepository<ArticleCategoryEntity>, GenericRepository<ArticleCategoryEntity>>();
// Services
services.AddScoped<IArticleService, ArticleService>();
services.AddScoped<IArticleCategoryService, ArticleCategoryService>();
// Code omitted for brevity
}The IServiceCollection.AddScoped() method call creates a dependency with a “scoped” lifecycle. This means the object gets created a reused for each request made within that session. The interface is defined followed by the concrete implementation doing the actual heavy lifting. More information about this particular topic can be found here.
Constructor Injection
Consumers then simply utilize constructor injection; the dependencies are passed in through the parameters and mapped to private readonly variables.
public class ArticleService : IArticleService
{
private readonly IHostingEnvironment _hostingEnvironment;
private readonly IGenericRepository<ArticleEntity> _repo;
private readonly IMapper _mapper;
private readonly ILogger<ArticleService> _logger;
public ArticleService(
IHostingEnvironment hostingEnvironment,
IGenericRepository<ArticleEntity> repo,
IMapper mapper,
ILogger<ArticleService> logger)
{
_hostingEnvironment = hostingEnvironment;
_repo = repo;
_mapper = mapper;
_logger = logger;
}
}Generic Repository
The repository is meant to draw a line and decouple the database implementation (EF Core) from the applications business logic. By doing so, I can freely “swap” the data store mechanism. In fact, I could build the entire application without a database and use flat file storage if I wanted to – it’s now completely “pluggable”. The point being that the application should not care how data is retrieved or stored. By mixing the database implementation details, I would be creating what is called a “Leaky Abstraction” – tightly coupling the application to the database once again. A great example of a real-life scenario, would be software that allows you to choose your own database implementation when you install it.
The repository also has a generic interface, with a generic implementation. By doing so, I no longer have to create a repository for each entity. Duplicate code is also avoided by having one set of CRUD operations against the dataset. Let me show you what I mean by that – lets first have a closer look at how I implemented the database.
The IGenericRepository resides in the CleanArchitecture.Core project, the central business logic that does not rely on any other project within the solution. This interface defines the input and output of how data flows to/from the application’s core layer. I implement this interface in the GenericRepository class within the CleanArchitecture.Infrastructure project. Outlined below:
public class GenericRepository<TEntity> : IGenericRepository<TEntity>, IDisposable
where TEntity : class, IEntity
{
private readonly ApplicationDbContext _dbContext;
public GenericRepository(ApplicationDbContext dbContext)
{
_dbContext = dbContext;
}
public async Task<IEnumerable<TEntity>> GetAll()
{
return await _dbContext.Set<TEntity>()
.AsNoTracking()
.ToListAsync();
}
public async Task<IEnumerable<TEntity>> GetPaginated(int page, int size)
{
return await _dbContext.Set<TEntity>()
.Skip((page - 1) * size)
.Take(size)
.AsNoTracking()
.ToListAsync();
}
public async Task<TEntity> GetById(int id)
{
return await _dbContext.Set<TEntity>()
.AsNoTracking()
.FirstOrDefaultAsync(e => e.Id == id);
}
public async Task Create(TEntity entity)
{
await _dbContext.Set<TEntity>().AddAsync(entity);
await _dbContext.SaveChangesAsync();
}
public async Task Update(int id, TEntity entity)
{
_dbContext.Set<TEntity>().Update(entity);
await _dbContext.SaveChangesAsync();
}
public async Task Delete(int id)
{
var entity = await GetById(id);
_dbContext.Set<TEntity>().Remove(entity);
await _dbContext.SaveChangesAsync();
}
public void Dispose()
{
if (_dbContext != null)
{
_dbContext.Dispose();
}
}
}This one class now handles all Create, Read, Update, Delete (CRUD) operations against our dataset. Without this, I would need a repository for each entity/table I intend to utilize – the benefits scale! This is extremely powerful stuff.

Logging
Logging is even decoupled from the application, and pluggable for all the same reasons. Right now, it uses NLog for its implementation, but I could easily add another specialized logger or switch entirely.
Conclusion
I had a blast working on this and have already used it as a base for other new projects. There is no reason to start from “File -> New” every time, and I encourage you to do yourself a favor – build your base toolset. I also hope you learned something new about clean architecture, I know I did while making this. I’m going to continue to add features that belong in a base project as necessary, so make sure to watch/star the project on github for updates. Even feel free to suggest your own!
Talent is a pursued interest. Anything that you’re willing to practice, you can do – Bob Ross
Thank you for reading! Reach out to me in the comments below with any questions, or just to say hi! 🙂